#include <SteepestDescent.h>
Diagram dziedziczenia dla SteepestDescent
Gradientowa metoda kierunków poprawy.
Podstawą teoretyczną metody są dwa twierdzenia:
1. Jeśli istnieje taki kierunek 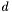 , że
, że
![\[ (\nabla f(x))^T d < 0 , \]](form_549.png)
to jest kierunkiem poprawy:
![\[ f(x + \tau d) < f(x) , \]](form_550.png)
gdzie 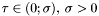 .
.
2. Dla liniowego modelu funkcji - rozwinięcia w szereg Taylora pierwszego rzędu:
![\[ f(x + \tau d) = f(x) + \tau d^T f'(x) + O(\tau^2) ,\]](form_552.png)
spośród wszystkich kierunków spełniających warunek z twierdzenia 1, kierunkiem najszybszego spadku jest
![\[ d = -\nabla f(x) . \]](form_553.png)
Informacje wejściowe:
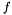 - minimalizowana funkcja
- minimalizowana funkcja 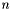 zmiennych,
zmiennych,
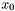 - dowolnie wybrany punkt startowy,
- dowolnie wybrany punkt startowy,
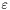 - dokładność warunku stopu,
- dokładność warunku stopu,
warunek stopu - do wyboru:
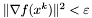
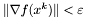
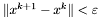 ,
, 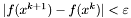 ,
, 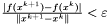 ,
,
Oznaczenia:
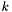 - numer aktualnej iteracji,
- numer aktualnej iteracji,
- aktualny kierunek poszukiwań,
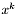 - aktualny punkt próbny,
- aktualny punkt próbny,
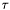 - długość wykonywanego aktualnie kroku.
- długość wykonywanego aktualnie kroku.
Procedura.
Krok wstępny:
Podstawiamy:
![\[ x^1 = x^0 , \]](form_554.png)
![\[ k = 1 . \]](form_34.png)
Krok 1:
Wyznaczamy kierunek przeciwny do gradientu:
![\[ d = -\nabla f(x^k) . \]](form_555.png)
Krok 2:
Sprawdzamy warunek stopu:
Jeśli 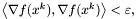 to STOP. W przeciwnym wypadku przechodzimy do kroku 3.
to STOP. W przeciwnym wypadku przechodzimy do kroku 3.
Krok 3:
Wykonujemy krok w kierunku o optymalnej długości :
![\[ \tau = \arg \min_{\tau} f(x^k + \tau d) , \]](form_557.png)
![\[ x^{k+1} = x^k + \tau d . \]](form_558.png)
Podstawiamy 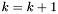 i przechodzimy do kroku 1.
i przechodzimy do kroku 1.
Uwagi.
Metoda opiera się na liniowym modelu funkcji (patrz twierdzenie 2) i dla funkcji wyższego rzędu jest najczęściej wolno zbieżna. Podstawową wadą, wpływającą na wolną zbieżność, jest "zygzakowaty" charakter przebiegów optymalizacji. Dokładne metody minimalizacji w kierunku (a taka jest tu wykorzystywana w kroku 3) zatrzymują się w punkcie, w którym gradient funkcji 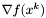 jest prostopadły do aktualnego kierunku poszukiwań
jest prostopadły do aktualnego kierunku poszukiwań 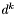 . Kolejny kierunek
. Kolejny kierunek 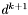 będzie, zgodnie z podstawowym założeniem metody, równoległy do gradientu. W ten sposób metoda w całym swym przebiegu operuje tylko dwoma prostopadłymi do siebie kierunkami, silnie zależnymi od punktu początkowego.
będzie, zgodnie z podstawowym założeniem metody, równoległy do gradientu. W ten sposób metoda w całym swym przebiegu operuje tylko dwoma prostopadłymi do siebie kierunkami, silnie zależnymi od punktu początkowego.
Metoda zaimplementowana na podstawie opisu zamieszczonego w:
Findeisen W., Szymanowski J., Wierzbicki A.: Teoria i metody obliczeniowe optymalizacji. Warszawa, PWN 1977.