#include <Marquardt.h>
Diagram dziedziczenia dla Marquardt
Metoda Marquardta jest udaną próbą połączenia korzystnych właściwości metod największego spadku i Newtona. Metoda Newtona zbiega się szybko w pobliżu minimum, natomiast metoda Cauchy'ego w dużym od niego oddaleniu.
Algorytm metody:
Oznaczenia:
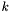 - numer aktualnej iteracji
- numer aktualnej iteracji
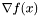 - gradient w punkcie
- gradient w punkcie 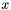
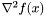 - macierz hesjanu w punkcie
- macierz hesjanu w punkcie
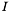 - macierz jednostkowa
- macierz jednostkowa
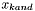 - kandydat na punkt w następnej iteracji (odrzucany po kroku próbnym gdy nie nastąpiło zmniejszenie wartości funkcji celu)
- kandydat na punkt w następnej iteracji (odrzucany po kroku próbnym gdy nie nastąpiło zmniejszenie wartości funkcji celu)
Dane potrzebne do obliczeń:
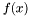 - minimalizowana funkcja celu
- minimalizowana funkcja celu
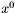 - punkt startowy
- punkt startowy
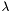 - współczynnik wagi macierzy jednostkowej
- współczynnik wagi macierzy jednostkowej
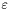 - wymagana dokładność
- wymagana dokładność
warunek stopu - do wyboru:
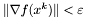
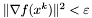
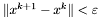 ,
, 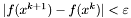 ,
, 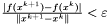 .
. 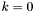 ..
..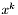 jako wynik. W przeciwnym wypadku przejdź do kroku 2.
jako wynik. W przeciwnym wypadku przejdź do kroku 2.
![\[ x_{kand} = x^k + \tau^k \]](form_250.png)
gdzie:
![\[ \tau^k = -[\nabla^2 f(x^k) + \lambda I]^{-1} \nabla f(x^k) \]](form_251.png)
Krok 3:
Jeśli 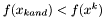 , to przejdź do kroku 4. W przeciwnym wypadku przejdź do kroku 5.
, to przejdź do kroku 4. W przeciwnym wypadku przejdź do kroku 5.
Krok 4:
Podstaw:
![\[ \lambda = \frac{1}{2} \lambda \]](form_252.png)
![\[ x^{k+1} = x_{kand} \]](form_253.png)
![\[ k=k+1 \]](form_254.png)
, a następnie przejdź do kroku 1.
Krok 5:
Podstaw 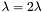 i przejdź do kroku 2.
i przejdź do kroku 2.
Uwagi:
W algorytmnie nie ma minimalizacji w kierunku, gdyż długość kroku reguluje już współczynnik . Na początku działania algorytmu wartość współczynnika musi być bardzo duża aby wartości na przekątnej macierzy jednostkowej miały większe znaczenie dla sumy we wzorze na kierunek. Z każdym udanym krokiem (tzn. takim, dla którego wartość funkcji w x maleje) lambda zmniejsza się o połowę aż do momentu, w którym to wartości hesjanu stają się ważniejsze dla wyznaczania kierunku. Podobnie jak w innych metodach, na początku działania algorytmu zmienne określające odległość dwóch ostatnich punktów i różnicę wartości funkcji w tych punktach mają wartości DBL_MAX. Wynika z tego, że algorytm może się zatrzymać bez wykonania żadnej iteracji jedynie w przypadku użycia kryterium "gradientowego". Jest to zachowanie jak najbardziej pożądane.
Algorytm zaimplementowano na podstawie:
Ostanin. A: Metody i algorytmy optymalizacji, Wydawnictwo Politechniki Białostockiej, Białystok, 2003<>